- Принципы работы
- Плюсы и минусы
- Где применяются
- Примеры слоя в keras
- Какая размерность сигнала на выходе из рекуррентного слоя
- Как соединять несколько рекуррентных слоёв подряд
- Как соединить рекуррентные слои с одномерной свёрткой и полносвязными слоями
Рекуррентные нейронные сети (РНС, англ. Recurrent neural network; RNN) — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).
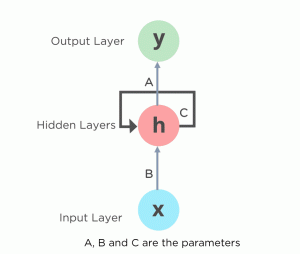
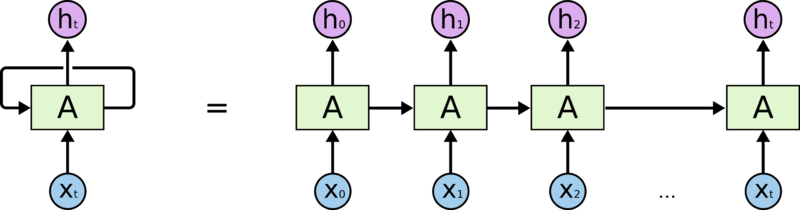
Плюсы – возможность обработки последовательностей, минусы – проблема исчезающего градиента, потребляют много ресурсов для обучения. Чем длиннее обрабатываемая последовательность, тем меньше меняется веса в начале последовательности.
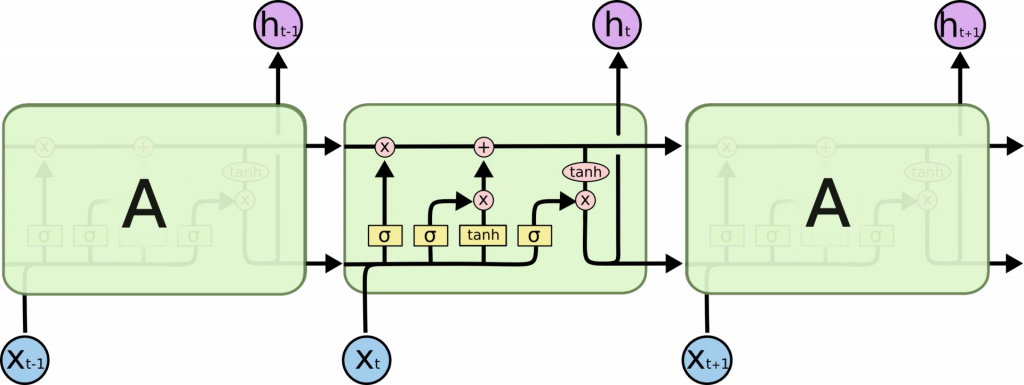
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# Импорты import numpy as np from keras.preprocessing import sequence from keras.models import Sequential from keras.layers import Dense, Activation, Embedding from keras.layers import LSTM from keras.datasets import imdb # Устанавливаем seed для обеспечения повторяемости результатов np.random.seed(42) # Указываем количество слов из частотного словаря, которое будет использоваться (отсортированы по частоте использования) max_features = 5000 # Загружаем данные (датасет IMDB содержит 25000 рецензий на фильмы с правильным ответом для обучения и 25000 рецензий на фильмы с правильным ответом для тестирования) (X_train, y_train), (X_test, y_test) = imdb.load_data(nb_words = max_features) # Устанавливаем максимальную длину рецензий в словах, чтобы они все были одной длины maxlen = 80 # Заполняем короткие рецензии пробелами, а длинные обрезаем X_train = sequence.pad_sequences(X_train, maxlen = maxlen) X_test = sequence.pad_sequences(X_test, maxlen = maxlen) # Создаем модель последовательной сети model = Sequential() # Добавляем слой для векторного представления слов (5000 слов, каждое представлено вектором из 32 чисел, отключаем входной сигнал с вероятностью 20% для предотвращения переобучения) model.add(Embedding(max_features, 32, dropout = 0.2)) # Добавляем слой долго-краткосрочной памяти (100 элементов для долговременного хранения информации, отключаем входной сигнал с вероятностью 20%, отключаем рекуррентный сигнал с вероятностью 20%) model.add(LSTM(100, dropout_W = 0.2, dropout_U = 0.2)) # Добавляем полносвязный слой из 1 элемента для классификации, в качестве функции активации будем использовать сигмоидальную функцию model.add(Dense(1, activation = 'sigmoid')) # Компилируем модель нейронной сети model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy']) # Обучаем нейронную сеть (данные для обучения, ответы к данным для обучения, количество рецензий после анализа которого будут изменены веса, число эпох обучения, тестовые данные, показывать progress bar или нет) model.fit(X_train, y_train, batch_size = 64, nb_epoch = 7, validation_data = (X_test, y_test), verbose = 1) # Проверяем качество обучения на тестовых данных (если есть данные, которые не участвовали в обучении, лучше использовать их, но в нашем случае таковых нет) scores = model.evaluate(X_test, y_test, batch_size = 64) print('Точность на тестовых данных: %.2f%%' % (scores[1] * 100)) |
Изменение размерностей
model = Sequential()
model.add(Embedding( 200, 10, input_length= 1000)) 1000 x 10
model.add(LSTM( 64, return_sequences= True)) 1000 x 64
model.add(LSTM( 64, return_sequences= False)) 64
model.add(Dropout( 0.5)) 64
model.add(BatchNormalization()) 64
model.add(Dense( 100, activation= “relu”)) 100
model.add(Dropout( 0.5)) 100
model.add(Dense( 6, activation= ‘softmax’ )) 6
SimpleRNN
• Самый простой вариант рекуррентной сети
• Обучается быстро
• Низкие возможности обучения
GRU
• Средняя сложность
• Средняя скорость обучения
• Средние возможности обучения
LSTM
• Самая высокая сложность
• Дольше всего обучается
• Большие возможности обучения