- Принципы обучения с подкреплением
- Чем обучение с подкреплением отличается от других задач – классификация, регрессия и т.п.
- Принцип алгоритма Policy gradient – что подаётся на вход сети, а что прогнозируется?
- Принцип алгоритма DQN – что подаётся на вход сети, а что прогнозируется?
- Policy gradient: принцип распространения подкрепления в обратную сторону
- Policy gradient: принцип формирования loss в зависимости от подкрепления
- Примеры задач для обучения с подкреплением
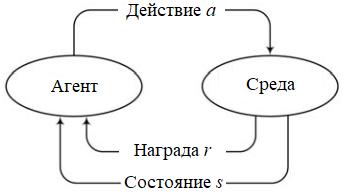
Обучение с подкреплением (англ. reinforcement learning, RL) —один из способов машинного обучения, связанный с принятием решений и контролем моторики. В ходе обучения с подкреплением испытуемая система (агент, в нашем случае им может выступать модель) учится, взаимодействуя с некоторой средой. Основная цель данного способа — изучить, как агент может научиться достигать своих целей в сложной неопределенной среде.
Policy gradient
Данный алгоритм использует следующий подход, в нем нейронная сеть получает на вход состояние и выдает policy — распределение вероятностей принятия того или иного действия. Агенту следует разыграть случайную величину в соответствии с полученным распределением, получить действие и передать его в среду. Так сеть работает в режиме предсказания действия. В режиме обучения используется несколько модифицированная сеть — она использует те же слои и те же веса, что и «рабочая» сеть, но имеет дополнительный вход для подачи величины advantage, которая представляет собой сумму дисконтированных наград, полученных в ответ на действия, предпринятые в прошлом в этом состоянии. Обучение происходит на данных о прошлых шагах, которые агент запоминает и использует для обучения. Обучение проводится
после завершения каждого эпизода, либо, как вариант, после N эпизодов. В качестве функции потерь используется кастомная функция — произведение логарифма вероятности действия на суммарную дисконтированную величину reward (т. е. advantage). Фактически в качестве потери используется математическое ожидание суммарной награды, получаемой к концу эпизода, взятое со знаком минус. Градиентный спуск ищет локальный минимум этой величины по отношению к весам сети, т. е. локальный максимум суммарной награды. Таким образом
оптимизируется стратегия агента — стремление к максимальной конечной сумме награды.
Deep Q-Learning
Этот алгоритм является усовершенствованием Q-Learning , в нем Q-таблица или функция заменяется на нейронную сеть, которая по заданному начальному состоянию предсказывает величины Q для каждого возможного действия. Далее остается либо выбрать действие с максимальной величиной Q (так называемое «жадное» поведение), либо продолжить исследование среды, выбрав случайное действие. На начальных
этапах обучения выбираются случайные действия, так как сеть еще не умеет с достаточной точностью предсказывать последствия действий. По мере обучения можно начинать действовать по рекомендациям сети.
…….
RL носит очень общий характер и охватывает все проблемы, связанные с принятием последовательности решений: например, управление двигателями робота, чтобы он мог бегать и прыгать, принятие деловых решений, таких как ценообразование и управление запасами, участие в видеоиграх и настольных играх. RL может даже применяться к контролируемым задачам обучения с последовательными или структурированными выходами.
40